16. 그룹 함수와 GROUP BY
그룹 함수는 검색된 여러 행을 이용 통계 정보를 계산하는 함수. 개발자는 복잡한 응용 개발이 필요한 통계 정보 검색을 그룹 함수를 이용하여 간단히 할 수 있음. 그룹 함수의 대상이 되는 행의 집합은 테이블 전체이거나 필요하다면, 조건 검색된 행이거나 일정한 단위로 묶인 행일 수 있음.
> 그룹함수
그룹함수는 여러 개의 행으로부터 하나의 계산되거나 추출한 값을 제공. 그룹 함수에 의한 결과는 대부분 그룹 함수 없이 응용으로 처리할 경우 많은 노력을 필요로 함

그룹 함수를 사용하는 경우 고려 사항
* NULL 값은 무시
* 반드시 단 하나의 값만을 반환
* GROUP BY 설정 없이 일반 컬럼과 기술 될 수 없음
-예제1. 사원의 급여 평균을 검색
SQL>SELECT AVG(sal), ROUND(AVG(sal))
2 FROM emp;

그룹 함수는 보통 통계정보를 계산하기 위해 사용되는 통계 함수인 경우가 많음. 사용 방식은 단일 행 함수 또는 그룹 함수와 같이 중첩해서 사용하는 것이 가능, 출력 값의 형식은 세션의 설정이나 중첩된 단일 함수를 이용해서 지정 가능
> 그룹 함수와 GROUP BY절
SQL>SELECT [DISTINCT / ALL] 컬럼 or 그룹함수, ...
2 FROM 테이블
3 WHERE 조건
4 GROUP BY Group 대상
5 ORDER BY 정렬대상 [ASC/DESC]
* SELECT 절에 그룹 함수와 컬럼이 같이 기술된 경우 해당 컬럼은 반드시 GROUP BY 절에 그룹화 돼야 함
* SELECT 절에 그룹 함수와 같이 쓰인 일반 컬럼이 GROUP BY 절에 기술되지 않으면 카디널리티(cardinality)가 일치하지 않아 'ORA-00937: not a single-group group function' 에러가 발생
* 예전에는 오름차순 정렬이 기본으로 제공되었지만 현재는 상황에 따라 다름. (ORDER BY 절을 이용 DESC로 변경 가능)
* 결과 값이 정렬되길 원한다면 반드시 ORDER BY절을 추가
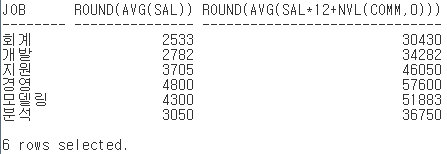
-예제4. 업무별 평균 급여, 평균 연봉과 부서별 평균 연봉을 검색
SQL>SELECT job, ROUND(AVG(sal)), ROUND(AVG(sal*12+NVL(comm,0)))
2 FROM emp
3 GROUP BY job;
SQL>SELECT d.dno, dname, ROUND(AVG(sal*12+NVL(comm,0)))
2 FROM dept d, emp e
3 WHERE d.dno = e.dno
4 GROUP BY d.dno, dname
5 ORDER BY d.dno;

GROUP BY절의 의미는 그룹 함수를 GROUP BY절에 지정된 컬럼의 값이 같은 행에 대해서 통계 정보를 계산하라는 의미
카디널리티(Cardinality)
RDB에서 카디널리티란 검색되는 각 컬럼의 행의 수를 의미하거나 컬럼에 저장된 값의 종류를 의미하기도 함. 예를 들면 보통 학번이나 주민번호와 같이 중복이 없는 컬럼의 카디널리티는 매우 높고 성별이나 학년등 중복 값이 많은 컬럼은 카디널리티가 낮음
이번 그룹 함수에서 이야가하는 카디널리티는 동시에 검색되는 각 컬럼과 항목들의 행의 개수를 의미. 그룹 함수를 사용하는 하나의 SELECT 문장에서 각 검색 항목들은 반드시 카디널리티가 일치해야 하며 이를 위해 GROUP BY절이 이용.
SELECT dno, AVG(sal) FROM emp;
AVG(sal)에서 검색된 값은 당연히 하나.(평균값이므로) 그러나 dno 컬럼의 값은 반드시 하나일 필요는 없음. RDBMS는 이렇게 검색되는 항목의 개수가 서로 다를 가능성이 있는 문장이 수행되면 'ORA-00937 : 단일 그룹의 그룹 함수가 아닙니다.' 에러를 발생. 이 때 일반 컬럼인 dno를 'GROUP BY'절에 기술하면 dno 값이 같은 행을 기준으로 집합을 만들고 여기에 대해서 각각 AVG(sal)을 계산함으로 dno의 검색 항목 개수와 AVG(sal) 결과 값의 개수가 동일해 짐. 이제 카디널리티가 일치해졌으므로 검색문은 에러가 발생하지 않고 수행됨
'그룹 함수와 같이 검색되는 모든 컬럼은 반드시 GROUP BY절에 기술함'. 이것은 원칙!
GROUP BY와 정렬
보통 GROUP BY 절은 정렬을 수행한다고 알려져 있다. 그러나 오라클은 기본적으로 GROUP BY를 수행 할 때 정렬을 수행하지 않고 해시(Hash) 함수를 이용함. 그러므로 결과 값도 GROUP BY절에 기술된 컬럼으로 정렬 되서 검색되지 않음. 거의 대부분의 경우에 정렬보다는 해시의 수행 성능이 더 빠르기 때문. 만일 정렬된 검색 결과를 얻고자 한다면 반드시 ORDER BY 절을 기술
▲
SQL>SELECT d.dno, dname ROUND(AVG(sal*12+NVL(comm,0)))
2 FROM dept d, emp e
3 WHERE d.dno = e.dno
4 GROUP BY d.dno, dname;
문장은 다음 문장과 동일
SQL>SELECT dno, dname, ROUND(AVG(sal*12+NVL(comm,0)))
2 FROM dept
3 WHERE d.dno = e.dno
4 GROUP BY d.dno, dname;
후자가 최신의 표현법이므로 이를 사용하는 것이 좋을 것 같다고 생각하겠지만 막상 현장에서는 옛 표현법 씀, 그러나 가능한 새로운 표현법을 사용하길 권장
<문제>
1. 30번 부서의 업무별 연봉의 평균을 검색
(단. 출력 양식은 소수이하 두 자리까지 통일된 형식으로 출력)
SQL>select job, to_char(avg(sal*12+nvl(comm,0)),'9999999.99')
2 from emp
3 where dno = 30
4 group by job;

2. 물리학과 학생 중에 학년별로 성적이 가장 우수한 학생의 평점을 검색
SQL>select syear, max(avr)
2 from student
3 where major = '물리'
4 group by syear
5 order by syear;

3. 학년별로 환산 평점의 평균값을 검색
SQL>select syear, TO_CHAR(avg(avr), '9.99')
2 from student
3 group by syear
4 order by syear;

4. 교수별로 현재 수강중인 학생의 수를 검색
SQL>select p.pname, count(*)
2 from professor p, course c, score sc
3 where c.pno = p.pno AND c.cno = sc.cno
4 GROUP BY p.pname, p.pno;

5. 화학과 1학년 학생 중 평점이 평균 이하인 학생을 검색
SQL>select sname, avr
2 from student
3 where major = '화학'
4 and syear = 1
5 and avr <= (select avg(avr) from student where major = '화학' and syear = 1) ;

17. 그룹 함수와 HAVING
그룹 함수를 포함한 조건은 일반 조건과 계산하는 과정이 상당히 다름. 일반 조건의 경우 컬럼의 값을 단지 조건과 비교하면 되지만 그룹 함수의 결과를 조건으로 하는 경우 GROUP BY 절의 사용 유무에 따라 결과 값이 달라지므로 조건에 그룹함수가 포함된 경우 이것은 일반 조건과 동일한 시점에 처리 할 수 없음
SQL은 그래서 HAVING 절을 제공
> 그룹 함수와 HAVING절
HAVING 절은 해석상 WHERE 절과 동일. 단 조건 내용에 그룹 함수를 포함하는 것 만을 포함. 일반 조건은 WHERE절에 기술하지만 그룹 함수를 포함한 조건은 HAVING절에 기술
SELECT 구문의 마지막 추가 구문
SQL>SELECT [DISTINCT/ALL] 컬럼 or 그룹함수, ...
2 FROM 테이블
3 WHERE 조건
4 GROUP BY Group 대상
5 HAVING < 그룹 함수 포함 조건 >
6 ORDER BY 정렬대상 [ASC/DESC]
* HAVING : 조건 중에 그룹 함수를 포함하는 조건을 기술
* HAVING 절은 그룹 된 결과에 대한 조건이므로 가능한 GROUP BY 절 뒤에 기술하는 것을 권함
GROUP BY 절에 따른 그룹 함수 결과 값의 변화
-예제3. 부서 중 가장 급여를 많이 받는 부서를 검색
SQL>SELECT dno, AVG(sal)
2 FROM emp
3 group by dno
4 having avg(sal) = (select max(avg(sal)) from emp group by dno);

중첩된 그룹 함수를 사용한 경우 GROUP BY 절에 기술한 컬럼일지라도 카디널리티 문제로 SELECT 절에 검색할 수 없음을 알게됨. 이런 경우 위 예제와 같이 서브 쿼리를 이용하면 해당 컬럼을 검색 할 수 있음. 이 구문은 매우 전형적으로 쓰이는 구문이므로 구조를 기억해 두면 많은 부문에서 활용 가능
<문제>
1. 근무 중인 직원이 4명 이상인 부서를 검색(부서번호, 인원) (4명이상이 없어 1명이상으로 수정)
SQL>select dno, count(*)
2 from emp
3 group by dno
4 having count(*) > 1;

2. 업무별 평균 연봉이 2만불 이상인 업무를 검색
SQL>select job, TRUNC(avg(sal*12+nvl(comm,0)))
2 from emp
3 group by job
4 having avg(sal*12+nvl(comm,0)) >= 20000;

3. 각 학과의 학년별 인원중 인원이 6명 이상인 학년을 검색
SQL>select major, syear, count(*)
2 from student
3 group by major, syear
4 having count(*) > 1;

4. 인원 수가 가장 많은 학과를 검색
SQL>select major,count(*)
2 from student
3 group by major
4 having count(*) = (select max(count(*)) from student group by major);

5. 학생 중 기말고사 성적이 가장 낮은 학생의 정보를 검색
SQL>select sno, TRUNC((avg(result)))
2 from score
3 group by sno
4 having avg(result) = (select min(avg(result)) from score group by sno);

댓글 없음:
댓글 쓰기