18. DML(INSERT, UPDATE, DELETE) 문의 이해
DML(Data Mainpulation Language)은 데이터베이스에 데이터를 입력, 수정, 삭제하는 명령어. DML은 SELECT 문장과는 달리 데이터베이스의 내용을 변경하는 작업을 수행함으로 이전보다는 훨씬 주의 깊게 계획되고 실행돼야 함 이렇게 DML작업은 안전한 작업과 결과가 요구됨으로 이를 위해 오라클을 트랜잭션이라는 단위로 일련의 작업 과정을 관리
>INSERT, UPDATE, DELETE
SQL>INSERT IN <테이블> [ (컬럼, 컬럼, ....)]
2 VALUES (값, 값, ...);
* INSERT는 하나의 행만을 삽입
- INSERT의 새로운 표준은 여러 개의 행을 삽입할 수 있도록 하고 있지만 오라클은 아직 지원하지 않음
* 컬럼 리스트와 VALUES 절의 값은 반드시 1:1로 대응
* 테이블의 모든 컬럼에 값을 입력하는 경우 컬럼 리스트를 생략 가능
- VALUES 절에 기술하는 값의 순서는 DESC 명령으로 확인된 테이블의 컬럼 순서와 일치해야 함
* 입력되는 값이 숫자가 아닌 경우 반드시 단일 인용 부호를 사용
* INSERT에서 생략된 컬럼은 NULL을 입력
* 명시적으로 NULL을 입력 할 경우 'NULL'을 기술
* 값 대신에 DEFAULT를 기술하면 테이블에 정의된 DEFAULT 값이 입력
SQL>UPDATE 테이블
2 SET 컬럼 = 값, 컬럼 = 값, ...
3 [WHERE 조건];
* 컬럼의 값을 수정
* WHERE 절을 생략하면 모든 행의 지정된 컬럼 값이 수정
* 여러 컬럼의 값을 동시에 수정 할 수 있음
* 값 대신에 DEFAULT를 기술하면 테이블에 정의된 DEFAULT 값으로 변경
SQL>DELETE FROM 테이블
2 [WHERE 조건];
* 행 단위로 데이터를 삭제
* 조건이 없는 경우 테이블의 모든 행을 삭제
* 테이블을 삭제해도 테이블의 물리적인 구조는 변하지 않음
SQL>COMMIT;
* 작업을 완료
* 모든 DML 문을 수행한 후 작업을 완료 할 때 반드시 필요
SQL>ROLLBACK;
* 작업을 취소
* 모든 DML 문을 수행한 후 작업을 취소 할 때 반드시 필요
데이터를 입력하고 수정하고 삭제하는 명령은 DB를 운영하는데 핵심적인 요소지만 간혹 DB의 운영 형태에 따라 DML중에 일부가 불필요하거나 제한되는 경우가 있음. 그러나 보통의 데이터베이스에서 정보 입력, 수정, 삭제는 기본적인 작업임. 보통의 프로그램에서는 기본적인 형태의 DML 문장을 이용함으로 여기에 제시된 실습만으로도 불편하지 않지만 DBA거나 DB를 관리하는 작업을 수행하는 경우라면 다양한 작업을 위해 특수한 DML을 수행하는 경우도 많음
-예제1. Dept 테이블의 모든 데이터를 삭제한 다음 ROLLBACK을 수행한 다음 결과를 확인
SQL>DELETE FROM dept;
SQL>SELECT * FROM dept;
SQL>ROLLBACK;
SQL>SELECT * FROM dept;

19. 서브 쿼리를 이용한 DML문과 다이렉트 로드
다량의 DML 작업을 수행하는 경우 서브 쿼리문을 이용 하는 경우가 많음. INSERT 작업에 대량 데이터를 입력 할 때 서브 쿼리를 이용하는 것은 매우 유용하고 빠른 작업 방법임. 특히 메모리를 통하지 않고 직접 데이터를 디스크에 입력하는 다이렉트 로드를 같이 사용하면 작업 효과는 배가 됨.
> 서브 쿼리를 이용한 INSERT
SQL>INSERT IN [/*+ APPEND */] 테이블 [NOLOGGING] [(컬럼, 컬럼, ...)]
2 SELECT 문장
* 서브 쿼리 (SELECT 문)에 검색된 행을 입력 값으로 사용
* 한 번에 많은 행을 입력 가능
* 컬럼 리스트와 SELECT 문의 컬럼이 1:1로 대응 되어야 함
* SELECT 문에 사용한 서브 쿼리 문과는 달리 괄호를 쓰지 않음
* /*+ APPEND */
- 다이렉트 로드를 이용
- 대량의 입력 작업을 더 빠르게 작업
*[NOLOGGING]
- 로그 정보를 남기지 않음으로 입력 작업이 빨라짐
- 장애 발생 시 복구 불가
-예제2. 각 사원의 정보와 근무지를 emp3 테이블에 저장
SQL>DESC emp3

SQL>INSERT /*+ APPEND */ INTO emp3 NOLOGGING (eno, ename, dno, dname)
2 SELECT eno, ename, d.dno, dname
3 FROM emp e, dept d
4 WHERE d.dno = e.dno;

SQL>SELECT * FROM emp3;
SQL>COMMIT;
SQL>SELECT * FROM emp3;

SELECT 작업이나 DML 작업은 모두 메모리에서 이루어짐. 오라클은 SGA라는 메모리 영역 내에 데이터베이스 버퍼 캐시(Database Buffer Cache)라는 영역을 작업 공간으로 이용함. 특별한 언급이 없는 이상 모든 데이터의 입력, 수정, 삭제는 모두 데이터베이스 버퍼 캐시에서 작업되고 이렇게 작업된 내용은 일정한 규칙에 따라 데이터 파일에 적용. 오라클은 이렇게 입력, 수정, 삭제된 데이터를 즉시 파일에 기록하지 않고 일정 수준 모아서 작업하는 방법을 통해 디스크 접근 횟수와 양을 줄여 성능을 향상시킴. 이와 같은 작업 방식은 다수의 사용자가 데이터를 동시에 입출력하는 일반적인 환경에서 매우 효율적이지만 일괄적인 대량의 DML 작업이 수행되는 경우는 오히려 무척 비효율적인 방식이 됨. 다량의 DML 작업이 일괄적으로 발생하면 기존 방식에서는 일단 메모리(데이터베이스 버퍼 캐시)에 정보를 저장한 다음 이를 디스크에 반영하고 다시 메모리를 정리하는 등의 작업을 수행해야 함 다이렉트 로드(Direct load)는 이를 단순화해서 대량 DML 작업이 메모리를 통하지 않고 디스크에 직접 작업ㅇ르 수행. DML 작업을 다이렉트 로드로 작업하기 위해서는 '/*+ APPEND */'를 문장에 삽입
그리고 오라클은 안전한 시스템 운영을 위해 장애 발생 시 복구 할 수 있도록 DB에 변경을 가하는 모든 작업의 내역을 리두 로그(Redo log) 영역에 로그 정보로 보관. 그러나 대량의 DML 작업은 작업의 효율을 위해 이를 수행하지 않을 수 있음. 작업 성능을 위해 로그 정보를 남기지 않는다면, 'NOLOGGING' 옵션을 이용. 그러나 이렇게 복구가 불가능하도록 작업한 이후에는 장애에 대비한 백업을 잊지 않아야 함. 대량의 작업에서 다이렉트 로드와 노로깅 방식을 이용하면 작업 성능은 비약적으로 빨라지지만 작업의 안전도는 떨어질 수 밖에 없음.
다이렉트 로드를 이용 대량의 데이터를 테이블에 입력한 경우 입력되는 물리적인 위치가 일반 입력과 달라 트랜젝션을 마무리 하지 않고 검색하게 되면 'ORA-12838 : 병렬로 수정한 후 객체를 읽거나 수정 할 수 없습니다.' 라는 에러를 만나게 됨. 이것은 입력 데이터의 손상을 방지하기 위한 기능. 반드시 COMMIT 한 이후 검색해야 함.
▲ 원래 '/* */'의 용도는 실행과 무관한 주석이용하기 위한 것이었음. 여기에 '+'를 추가하여 힌트(hint)절로 이용하는데 힌트 절은 오라클에게 이 문장을 수행하는 최적의 방법을 조언
> 서브 쿼리를 이용한 UPDATE
SQL>UPDATE 테이블
2 SET 컬럼명 = (SELECT 문장),
3 컬럼명 = (SELECT 문장), ...
4 [WHERE 조건] ;
SQL>UPDATE 테이블
2 SET (컬럼, 컬럼, ....) = (SELECT 문장)
3 [WHERE 조건] ;
* UPDATE 문의 SET절에는 단일 행 서브 쿼리나 다중 열 서브 쿼리를 이용할 수 있음
- 다중 열인 경우도 반드시 결과 행은 하나여야 함
- SET 절에는 단일 행 연산자만 기술 가능
* 서브 쿼리에 의해 검색되는 Data는 반드시 수정되는 컬럼명과 1:1 대응 되어야 함
* Set 절에는 단일행 서브 쿼리만 허용되지만 WHERE 절의 서브 쿼리는 연산자에 따라 달라짐
<문제>
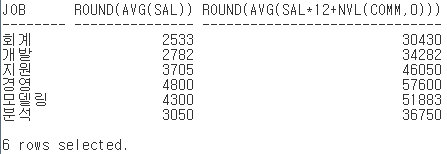
1. st_score_avg 테이블에 각 학생의 평점을 학과별, 과목별로 입력
st_score_avg
SQL>DESC st_score_avg;
테이블 생성
create table st_score_avg (
sno VARCHAR2(6),
sname VARCHAR2(10),
syear number(1),
avg_result number(3)
);
sno VARCHAR2(6),
sname VARCHAR2(10),
syear number(1),
avg_result number(3)
);
테이블에 값 입력
INSERT /*+ APPEND */ INTO st_score_avg NOLOGGING
(sno, sname, syear, avg_result)
select s.sno, s.sname, s.syear, sc.result
from student s, course c, score sc
where s.sno = sc.sno and c.cno = sc.cno;

2. 화학과 학생이 수강하는 과목을 강의하는 교수의 부임일자를 1년 늦도록 수정
20. 트랜잭션(Transaction)과 잠금(Lock)의 이해
응용 프로그램 개발 과정에서 잘못 설계된 트랜잭션으로 인해 많은 문제가 발생함 문제의 대부분은 업무 분석의 미숙이나 트랜잭션이 일으키는 잠금(Lock)에 대한 이해가 부족해서 나타나는 것들임. DBA와 같이 DBMS를 운영하는 직군의 사람들에 비해서 개발자나 사용자의 경우 이에 대한 이해가 많이 부족한 경우가 많음
트랜잭션이란
트랜잭션은 반드시 함께 실행되는 작업의 단위를 의미함. 즉 사용자의 의도에 따라 여러개의 문장으로 구성된 트랜잭션은 반드시 동시에 실행(COMMIT) 되거나 취소(ROLLBACK)됨. RDBMS는 트랜잭션을 통해 작업의 단위를 결정함으로써 작업 결과의 신뢰성을 확보
예를 들어 금융 거래 중에 계좌 이체를 생각해보면. A라는 사람이 소유 계좌의 금액 중 100만원을 B라는 사람의 계좌로 이체한다면 최소 두 가지 작업이 수행돼어야 함. 첫 번째 작업은 A의 계좌에서 100만원이 출금되는 것이고, 두 번째는 B의 계좌에 100만원이 입금되는 것임. 그런데 만약 A의 계좌에서 100만원이 출금 된 이후 두 번째 작업이 수행되기 전에 시스템이 다운된다면 B의 계좌에 돈이 입금되지 않고 A의 계좌에서만 100만원만 없어지게 될 수 있다. 이런 문제를 방지하기 위해 두 개의 작업을 하나의 트랜잭션으로 묶어 놓으면 두 개의 작업이 모두 실행되지 않으면 모두 취소됨으로 거래의 신뢰도를 높일 수 있음. 즉 두 번째 작업인 입금이 실행되지 않으면 첫 번째 출금 작업은 자동으로 취소되도록 함으로써 거래의 신뢰성을 확보하는 것. 트랜잭션은 이와 같이 더 이상 쪼갤 수 없는 최소한의 작업 단위로써 다음의 특징을 갖음
* 원자성(Aotomicity)
- 트랜잭션은 최소의 작업 단위로서 전체가 처리되거나 취소 될 수 있지만 일부만 처리 될 수는 없음
* 일관성(Consistency)
- 트랜잭션이 실행된 이후 데이터베이스의 무결성은 반드시 유지 되어야 함
* 독립성(Isolation)
- 트랜잭션을 여러 개 동시에 실행하더라도 각각의 트랜잭션은 서로 영향을 줄 수 없음.
즉 실행이 종료되지 않은 트랜잭션의 결과는 다른 트랜잭션에서 참조하는 것이 불가능
* 영속성(Durability)
- 종료된 트랜잭션의 결과는 반드시 데이터베이스에 반영되어야 함
트랜잭션의 시작과 종료
1. 시작
* 이전 트랜잭션이 종료된 이후 DML(INSERT, UPDATE, DELETE)문장이나 DDL(CREATE, ALTER, DROP, TRUNCATE), DCL(GRANT, REVOKE) 문장에 실행됐을 때 시작
2. 종료
* COMMIT이나 ROLLBACK 명령이 실행될 때 종료
* DDL이나 DCL문장의 실행이 완료되면 자동으로 종료
* 사용자의 정상 종료 시에 종료
* 데드락(Deadlock)이 걸리면 트랜잭션의 일부만 종료
트랜잭션은 하나의 세션에서 단지 하나만 시작할 수 있으며 DML인 경우 반드시 COMMIT이나 ROLLBACK으로 종료 하지만 DDL이나 DCL의 경우 문장이 실행되고 난 후 자동으로 종료. 오라클은 SAVE POINT 명령을 이용 트랜잭션의 과정을 제어 가능
트랜잭션과 언두 세그먼트(Undo segment)
DML 작업을 ROLLBACK하기 위해서는 작업 이전 데이터를 어딘가에 저장해 두어야 함. 오라클은 작업이 발생하면 즉시 테이블의 내용을 변경함으로서 DELETE나 UPDATE문을 실행하면 테이블의 정보가 즉시 변경됨. 그런데 사용자가 ROLLBACK을 실행하면 DML작업에 의해서 변경된 정보를 이전 정보로 환원해야하는데 만일 작업 이전 정보를 저장하고 있지 않다면 ROLLBACK을 실행할 수 없게 됨. 이렇게 작업 이전 정보를 저장하고 관리하는 것은 트랜잭션의 기본적인 기능이며 이를 위해 오라클은 언두 테이블스페이스와 언두 세그먼트라는 물리적인 구조를 이용. 이들은 모두 자동으로 관리되며 사용자는 이들 정보를 직접 볼 수 없고 단지 트랜잭션에서 사용.
트랜잭션 과정
테이블에 INSERT 작업이 수행될 때, 입력 데이터가 INSERT 구문이 실행될 때 테이블에 저장될지 아니면 COMMIT이 실행될 때 저장될지의 문제는 RDBMS의 구조에 따라 다름. 오라클은 INSERT문이 실행 될 때 행이 입력되고 입력된 행에만 잠금이 걸리며 COMMIT될 때 잠금이 풀림. 물론 UPDATE나 DELETE도 수행 과정은 동일. UPDATE 문장을 통해 트랜잭션 과정을 살펴보면
1. UPDATE 문장이 테이블에 발생하면, 문장 수행을 위해 사용할 언두 세그먼트(segment)를 결정
2. 테이블에 저장되어있던 원래 값이 언두 세그먼트에 저장
3. UPDATE 된 값이 테이블에 저장
4. 값이 변경된 행은 독점 잠금이 발생
독점 잠금이란 현재 세션 이외에는 접근을 불허하는 잠금으로 다른 세션으로 접속시에는 Undo Segment의 값을 보게 됨. 오라클에서는 행 단위로 독점 잠금을 수행하지만 SQL 서버에서는 페이지 단위로 독점 잠금을 수행. 한 페이지에 여러 행이 묶여 있기 때문에 페이지 단위로 독점 잠금을 수행하면 다른 행에도 접근하지 못할 수 있음.
5. 테이블에는 공유 잠금이 발생
6. 트랜잭션이 COMMIT 되면 잠금은 해제되고 변경된 값은 영구히 저장
7. 트랜잭션이 ROLLBACK 되면 언두 세그먼트에 저장했던 원래 값을 테이블로 환원하고 잠금이 해제

주제에서 약간 벗어난 이야기지만 트랜잭션 과정에 관해서 RDBMS의 대표적인 제품인 오라클과 SQL 서버의 차이점을 살펴보면 먼저 오라클은 그림과 같이 DML 명령어가 수행 될 때 데이터가 테이블에 적용되지만 SQL 서버는 COMMIT을 수행할 때 데이터가 테이블에 적용됨. 그리고 오라클은 행마다 독점 잠금을 걸지만 SQL 서버는 I/O 단위 인 페이지 전체에 독점 잠금을 검. 이로 인해 SQL 서버의 경우 실제 트랜잭션이 발생하지 않은 행들까지 독점 잠금이 발생할 수 있음. 간혹 이를 오해해서 오라클의 물리적인 I/O 단위를 혼동하는 경우가 있는데 오라클의 물리적인 I/O 단위는 SQL 서버의 페이지와 유사한 블록(BLOCK) 단위이긴 하지만 보통의 트랜잭션에서 잠금 대상이 아님
독점 잠금(Exclusive lock)과 공유 잠금(Share lock)
독점 잠금은 현재 세션이외에는 접근을 불허하는 잠금 방식. 이는 트랜잭션의 특징인 독립성을 보장하기 위한 것. 트랜잭션으로 행에 잠금이 발생하면 다른 세션에서는 해당 행을 검색할 수 없고, 단지 언두 세그먼트의 정보만 보게 됨. 그리고 이 때 테이블에는 공유 잠금이 발생하는데 이것은 DML 작업으로 행이 잠겨 있는 테이블에 대해서 DDL(DROP, ALTER)작업을 방지함.
실습에서 보는 바와 같이 트랜잭션은 잠금을 발생시키는데 이로 인해 잠금을 발생시킨 세션이외에 다른 세션들은 잠금이 발생한 테이블을 검색 할 때 잠금이 걸린 행에 대해서는 물리적으로 다른 영역인 언두 세그먼트를 읽음. 이에 따라 테이블의 정보가 이미 변경되었다 하더라도 이전 정보를 읽음. 이런 현상은 트랜잭션이 종료 될 때 까지 계속됨. 그러나 이렇게 지연된 트랜잭션에 의해 언두 영역을 읽는 것은 검색 시에 I/O량을 늘려서 성능을 저하시킴. 특히 OLTP(online transaction processing)와 같이 다량의 짧은 트랜잭션이 발생하는 시스템에서 지연된 트랜잭션은 시스템에 많은 부담을 줌. 이런 경우 트랜잭션을 가능하면 짧게 유지해서 이렇게 성능이 저하되는 현상을 감소 가능.
독점 잠금은 데이터에 대한 독점적인 사용을 획득하는 것으로 리소스에 걸리는 여러 개의 작업들의 독립성을 보장하는 방법임. 트랜잭션들은 실행 순서대로 행에 작업가능하고 이로 인해 대기 현상이 발생함. 오라클은 독점 잠금에 대해서 시간 순서대로 트랜잭션을 보장하며 이들 작업들은 앞의 트랜잭션이 종료되면 데이터에 대한 독점적인 접근을 보장 받음.
데드 락은 두 개의 트랜잭션이 서로 상대가 독점 락을 통해 점유한 리소스에 동시에 접근해서 둘 다 대기 상태가 될 때 발생. 데드 락은 이렇게 둘 이상의 트랜잭션이 서로 상대가 독점 락을 통해 점유한 리소스에 동시에 접근해서 둘 다 대기 상태가 될 때 발생. 데드 락은 이렇게 둘 이상의 트랜잭션이 서로 상대의 독점 락에 의해서 대기하는 현상. RDB뿐 아니라 OS등의 응용 시스템에서도 빈번히 나타나는 문제. 오라클은 데드 락을 발생시킨 세션의 마지막 명령을 보존하고 데드 락을 유발한 상대 세션의 마지막 명령을 ROLLBACK 시키는 것으로 데드 락을 해결. 이 때 세션 전체가 ROLLBACK 되는 것은 아님으로 주의.
21. 테이블 생성과 데이터 타입의 이해
DB에서 데이터를 저장하는 가장 기본적인 구조는 테이블(TABLE)임. 오라클에는 테이블 이외에 뷰(VIEW), 인덱스(INDEX), 시퀀스(SEQUENCE) 등 여러 개체가 있고 이들 중에 물리적인 공간을 갖는 개체를 세그먼트(SEGMENT)라고 분류하는데, 이 중 테이블은 사용자가 직접 조회 가능한 데이터를 저장하는 유일한 세그먼트임. 테이블은 DB에서 가장 중요한 개체이며 최종 사용자에게 DB는 단지 테이블의 모임으로 보일 만큼 테이블은 가장 핵심적인 단위임.
> 테이블 생성과 삭제
테이블은 행(Row)과 컬럼(Colum)으로 이루어진 매우 익숙한 형태의 자료구조임. 테이블과 같은 구조의 자료구조는 문서의 일반적인 형태로 DB 이전부터 사용되어 옴. 정보시스템과 무관하게 문서로 널리 사용되는 이것을 행과 열로 구성된 표 또는 도표라 부름.
정보 시스템에서 문서의 형태였던 도표의 구조를 도입해서 테이블로 사용한 것임. 초창기 파일 시스템을 기반으로 한 DB 시스템에서 레코드와 필드로 구성된 파일이 도표를 대신했찌만 RDB(Relatinal DataBase)가 본격적으로 사용되면서부터 행(Row)과 컬럼(Column)으로 구성된 테이블이 이를 대신.
SQL>CREATE TABLE 테이블 (
2 컬럼 데이터_타입 [DEFAULT default 값] [컬럼 레벨 제약조건],
3 컬럼 데이터_타입 [DEFAULT default 값] [컬럼 레벨 제약조건], 4 .............
5 [테이블 레벨 제약조건],
6 ........
7 );
* 데이터_타입
- 컬럼에 입력될 데이터의 종류와 크기를 결정
* DEFAULT
- 입력이 누락됐을 때 기본 입력 값을 정의
- Default 값을 지정하지 않으면 널 값이 저장
* 컬럼 레벨 제약 조건
- PK, FK, UK, CHECK, NOT NULL 등을 지정
* 테이블 레벨 제약 조건
- PK, FK, UK, CHECK 만 지정
- NOT NULL은 정의 불가
SQL>DROP TABLE 테이블
2 [CASCADE CONSTRAINT];
* 테이블을 삭제함
- OS와 비슷하게 테이블을 물리적으로 삭제하지 않고 휴지통에 넣어두어 나중에 복구 가능하도록 함.
- 공간이 부족하면 휴지통의 공간은 자동으로 재사용
- 삭제된 테이블은 BIN$로 시작하는 이름이 할당
* CASCADE CONSTRAINT : 테이블이 다른 테이블로부터 참조되는 경우 해당 제약 조건을 먼저 삭제한 후 테이블을 삭제
SQL>PURGE RECYCLEBIN;
* 휴지통에 저장된 모든 내용을 깨끗이 삭제
SQL>SELECT table_name
2 FROM user_tables;
* 'SELECT * FROM tab' 과 동일하게 소유한 테이블 목록을 검색
* user_tables와 같이 오라클의 메타 정보를 저장하고 검색하는 테이블을 데이터 딕셔너리 (Data Dictionary) 또는 딕셔너리(Dictionary)라 함
* user_tables에는 소유한 테이블 이름뿐 아니라 테이블의 물리적인 상태를 포함한 테이블에 대한 다양한 정보가 저장
SQL>SELECT table_name, column_name, data_type, data_length
2 FROM user_tab_columns
3 [WHERE table_name = 테이블;]
* 'DESC 테이블'과 동일한 내용을 검색
* User_tab_columns를 이용해서 테이블의 구조를 검색
* data_type : 컬럼의 데이터 타입
* data_length : 컬럼의 길이
테이블 생성에서 이름 규칙
* 문자로 시작
* 30자 이내
* 영문, 숫자, _, $, #만을 사용
- 한글 사용은 가능하지만 되도록 사용하지 않는 것이 좋음.
* 테이블의 이름은 동일한 유저(스키마) 안에서 유일해야 함
* 예약어는 사용이 불가능
* 대소문자를 구별하지 않음
- 생성 할 때 사용한 문자와는 관계없이 모든 이름은 대문자로 정의
- 테이블 이름은 딕셔너리에 저장되는데, 모두 대문자로 저장
데이터 타입
* 오라클은 다양한 데이터 타입을 제공
* 문자 타입
- VARCHAR2, CHAR, LONG, CLOB
* 숫자 타입
- NUMBER
* 날짜 타입
- DATA
* 이진 타입
- RAW, LONG RAW, BLOB, BFILE
* ROWID 타입
- ROWID
오라클에는 우리가 사용하는 어떤 언어보다도 많은 데이터 타입을 제공. 그러나 이것들은 대부분 PL/SQL 이라는 프로그래밍을 위해 제공되는 것들임. 일반적인 SQL문에서 이들을 사용하는 것은 별가치가 없음.
VARCHAR2, NUMBER, DATE 타입으로, 이 세 가지 타입이 전체 테이블의 99% 이상 사용.
 숫자인가 문자인가
숫자인가 문자인가
실무에서 어떤 컬럼의 데이터 타입을 정할 때 숫자인지 문자인지 결정하는 것은 결코 간단하지 않음. 예를 들면 계좌번호, 주민번호, 사번, 학번, ... 등과 같이 경계가 모호한 데이터들이 주변에 많기 때문임. 주민번호의 예를 들어 보면, 주민 번호는 숫자라고 생각 할 수 있지만, 문자임. 어떤 사람의 주민번호 앞자리가 061311이고 만약 이것이 숫자였다면 이것을 읽을 때 '육만삼천삼백십일'이라고 읽었을 것임. 하지만 이 값을 읽을 때 대부분의 사람들은 '영육일삼일일'이라고 읽음.
무엇이 문자이고, 숫자인지에 대한 명확한 답은 없지만 일반적이고 상당한 이유가 있는 답은 존재함. 그것은 컬럼의 데이터가 연산의 대상이 되는 것은 숫자로 정의하고 그렇지 않은 것은 일단 문자로 구별하는 것. 연산의 대상이 될 수 있는 예를 보면 월급, 보너스, 좌석의 수, 사원의 수 .. 등이 있음. 이들은 당연히 숫자형임. 반대로 연산의 대상이 아닌 경우는 사번, 학번 등이 있음. 앞에 예로든 주민 번호의 예를 보면, 주민번호를 대상으로 +,-,/,* 등의 사칙연산을 수행한 결과 값이 의미를 갖는다면 이것은 숫자, 하지만 의미가 없다면 문자로 간주함
데이터 딕셔너리(Data Dictionary)
데이터 딕셔너리는 데이터베이스의 상태나 내부 운영과 관련된 정보를 저장해주는 테이블.
이들 테이블을 물리적으로 특별한 공간에 저장되며 각 사용자의 관리 레벨에 따라 접근 가능한 목록이 달라짐. 보통은 DBA가 RDBMS를 관리하기 위해 사용하지만 일반 사용자도 자신의 여러 개체에 대한 정보를 조회하기 위해 사용 가능. 실제 딕셔너리 테이블들은 직접 검색하는 것이 아니라 뷰를 통해 검색하지만 어떤 경우든 SELECT 만 가능함으로 이를 구별 하는 것은 별 의미 없음.
딕셔너리는 원도우즈의 제어판과 비슷한 기능을 가진 것으로 이름이 항상 복수형이라는 특징 보유
딕셔너리 이름의 접두어
딕셔너리는 이름의 접두어만으로 접근 레벨을 짐작 할 수 있음. 접두어는 'DBA_', 'ALL_', 'USER_' 이렇게 세 가지가 있으며 각각의 의미는 다음과 같음
* DBA_ : 관리자만 검색 가능한 딕셔너리에 붙는 접두어
(DBA_TABLES, DBA_INDEXES, DBA_TABLESPACES, DBA_DATA_FILES, ...)
* ALL_ : 일반 사용자가 검색 가능한 딕셔너리, 접근 가능한 개체에 대한 정보를 담고 있음
(ALL_TABLES, ALL_CONSTRAINTS, ALL_INDEXES, ALL_VIEWS, ...)
* USER_ : 일반 사용자가 검색 가능한 딕셔너리, 소유하고 있는 개체에 대한 정보를 담고 있음
(USER_TABLES, USER_CONSTRAINTS, USER_INDEXES, USER_VIEWS, ...)
관리자는 DBA_ 접두어를 가진 딕셔너리를 이용하고 일반 사용자는 보통 USER_ 접두어를 가진 딕셔너리를 이용하는 데 11g 버전 기준으로 DBA_ 딕셔너리는 대략 700여개, USER_ 딕셔너리는 대략 400여개가 있음. 딕셔너리 목록은 DICT 테이블을 통해서 검색 가능함.
DICT 테이블의 전체 검색 결과는 현재 사용자가 접근 가능한 딕셔너리의 목록이므로 사용자와 무관하게 사용 가능.
22. 제약조건 이해와 설정 1 : PK, FK
제약 조선이란 테이블 단위에서 데이터의 무결성을 보장해주는 규칙. 제약 조건은 테이블에 데이터가 입력, 수정, 삭제되거나 테이블이 삭제, 변경될 경우 잘못된 트랜잭션이 수행되지 않도록 결함을 유발할 가능성이 있는 작업을 방지하는 역할을 담당. 특히 PK(Primary Key)와 FK(Foreign Key)는 테이블의 필수 요소로써 모든 테이블은 이들 둘 중 하나 이상을 반드시 포함하고 있음.
제약 조건
* 테이블 단위에서 정의되고 적용됨
* 종속성이 존재하는 경우 테이블의 삭제를 막음
* 자료가 삽입, 갱신, 삭제될 때마다 규칙이 적용.
* 일시적으로 활성화하거나 비활성화 하는 것이 가능
* USER_CONSTRAINTS, USER_CONS_COLUMNS 딕셔너리에서 검색
* 제약 조건은 개체처럼 관리되므로 반드시 이름이 필요. 제약 조건에 이름을 정의하지 않으면 오라클 서버가 자동으로 SYS_Cn 형태의 이름을 붙임
오라클에서 제공되는 제약조건들
* PRIMARY KEY
* FOREIGN KEY
* UNIQUE KEY
* NOT NULL
* CHECK
> PK와 FK의 정의
PK(Primary Key, 주키, 주식별자)
- PK는 테이블의 모든 데이터를 유일하게 식별해주는 컬럼. 예를 들어 데이터베이스에는 여러분을 나타내는 정보가 여러가지가 있음. 이름, 성별, 주소, 출신 학교 등등.. 이 중에 어떤 데이터가 연속적으로 여러분을 유일하게 구분 할 수 있는 데이터 인지 생각해보면 됨.
- 이 중에 주민번호, 학번, 사번 등의 데이터는 중복 없이 여러분의 데이터를 유일하게 구분 할 수 있도록 해주는 데이터 들임. 이들 데이터가 바로 PK가 됨. 이런 이유로 PK는 중복되지 않으면서 NULL일 수 없는 컬럼이 선택. 만일 PK를 주민번호로 했다면 이 때 이름이나 성별등의 데이터는 PK인 주민번호에 의해서 식별 됨. 다르게 표현하면 PK인 주민번호에 대해서 이름, 성별, 주소 등은 함수적 종속(functional dependency) 관계에 있다고 표현. PK의 가장 중요한 정의는 함수적 종속이라는 수학적인 정의임. PK가 없다면 RDB에서 그건 테이블이 될 수 없음.
FK(Foreing Key, 외부키, 외부식별자)
- FK는 테이블 간 관계(Relationship)를 의미. 사원 테이블의 부서번호 컬럼은 각 사원이 소속된 부서의 번호가 저장된 컬럼. 이 때 사원은 당연히 회사에 존재하는 부서에만 소속될 수 있음. 만일 회사에 총무부와 회계부서만 존한다면 모든 사원은 반드시 이 두 부서에만 속해야 함. 만일 어떤 사원이 존재하지 않는 부서에 소속된다면 어떨까? 이것은 부서 테이블을 확인함으로써 확인 가능함. 즉 사원 테이블의 부서번호 컬럼에는 부서 테이블의 부서번호 컬럼에 존재하는 데이터만 입력 가능함. 그런데 입력하는 사람이 입력 시점에 일일이 이를 확인하는 것은 어려운 일임. 이런 경우 사원 테이블의 부서 번호 컬럼에 FK를 설정해서 부서 테이블의 부서번호 컬럼을 참조하도록 한다면 사용자가 부서 테이블에 존재하지 않는 부서번호를 사원 테이블에 입력하는 것을 DBMS가 자동으로 막아줌. 이 때 우리는 사원 테이블과 부서 테이블 간에 관계라 하고 관계는 주로 FK로 표현.
> PK(Primary Key), FK(Foreign Key) 설정과 조회
- Primary Key 설정
SQL> CREATE TABLE 테이블 (
2 **내용**
3 CONSTRAINT 제약_조건 PRIMARY KEY (컬럼)
4 );
SQL> CREATE TABLE 테이블 (
2 컬럼 데이터_타입 CONSTRAINT 제약_조건 PRIMARY KEY, ****
* 테이블을 생성할 때 PK를 정의
* PK는 각 행을 고유하게 식별하는 역할을 담당
* 테이블 당 하나만 정의 가능
* 지정된 컬럼에는 중복된 값이나 NULL값이 입력 될 수 없음
* PK로 지정 가능한 컬럼이 여러 개 있을 때는 검색에 많이 사용되고 간단하고 짧은 컬럼을 지정
* 주 식별자, 주키, 주식별자 등으로 불림
* 고유 인덱스(Unique Index)가 자동으로 생성
- Foreign Key 설정
SQL> CREATE TABLE 테이블 (
2 ****
3 CONSTRAINT 제약_조건 FOREIGN KEY (컬럼)
4 REFERENCE 참조할_테이블 (참조할_컬럼) [ON DELETE CASCADE]);
SQL> CREATE TABLE 테이블 (
2 컬럼명 데이터_타입 CONSTRAINT 제약_조건 FOREIGN KEY
3 REFERENCES 참조할_테이블 (참조할_컬럼)
4 [ON DELETE CASCADE],
5 *************
* 테이블을 생성할 때 FK를 정의
* FK가 정의된 테이블이 하위(자식) 테이블
* 참조되는 테이블이 상위(부모) 테이블
* 상위 테이블은 미리 생성되어 있어야함
* 상위 테이블의 참조되는 컬럼에 존재하는 값만을 입력 할 수 있음
* 상위 테이블에 참조되는 행의 데이터는 FK를 위배하는 삭제나 변경이 불가능
* 상위 테이블은 FK로 인해 삭제가 불가능
* ON DELETE CASCADE : 참조되는 상위 테이블의 행에 대한 DELETE를 허용
- 하위 테이블의 행도 같이 지워짐
* 자료형이 반드시 일치해야 함
* 참조되는 컬럼은 PK이거나 UK(Unique Key)만 가능
* 외부키, 참조키, 외부 식별자 등으로 불림
▲
- 제약조건을 정의하는 방법은 NOT NULL을 제외하고 두 가지 방법이 제공.
하나는 컬럼을 정의하면서 같이 정의하는 방법으로 컬럼 레벨 정의라고 하고 하나는 테이블 생성 명령어 마지막에 기술하는 방법으로 테이블 레벨 정의라 함. 둘 중 어떤 것을 사용해도 상관없지만 가능한 테이블 레벨 정의를 사용하는 것이 가독성이 높음
제약 조건 조회
SQL> SELECT c.table_name, c.constraint_name, c.constraint_type, s.colum_name
2 FROM user_constraints c, user_cons_columns s
3 WHERE c.constraint_name = s.constraint_name
4 AND c.table_name in (검색_대상_테이블_목록)
5 ORDER BY c.table_name;
* 테이블에 정의된 제약 조건을 검색
* 'AND c.table_name in (검색_대상_테이블_목록)' 부분을 생략하면 소유한 모든 테이블의 제약조건을 검색
* constraint_name : CONSTRAINT 이름
* constraint_type : CONSTRAINT 타입
- P(PK), R(FK), U(UK), C(NOT NULL, CHECK)
SQL> SELECT p.table_name 상위테이블, p.constraint_name 상위제약조건,
2 c.table_name 하위테이블, c.constraint_name 참조제약조건
3 FROM user_constraints p, user_constraints c
4 WHERE c.r_constraint_name=p.constraint_name
5 AND p.table_name in (검색_대상_테이블_목록)
6 ORDER BY p.table_name;
* 지정한 테이블을 참조하는 테이블의 목록을 확인
* 하위 테이블이 존재하는 상위 테이블은 테이블 삭제가 불가능
테이블 상세 도표
- 테이블 상세 도표는 테이블의 구조를 한 눈에 파악 할 수 있는 간단한 도표임. 테이블의 구조와 관계는 보통 ERD(Entity-Relationship Diagram)를 이용하지만 본서가 모델링 과정을 다루지 않는 관계로 각 테이블의 정보를 도표로 정리 한 것. 보통 개체 상세도라고도 불리는 상세도에서 우리에게 필요한 부분만을 발췌함. 이를 통해 테이블의 구조, 참조 관계등을 명확히 파악할 수 있음. 테이블을 생성하기 전에 반드시 테이블에 대한 작업 계획이 완성돼야 하는데 그 중 가장 중요한 것이 이들 상세도표임.

▲ 내부 무결성과 외부 무결성
- 무결성은 데이터에 결함이 없음을 보장하는 성격을 의미. 이미 앞에서 개체 무결성과 관계 무결성에 대해서 살펴봄. 이번에는 무결성을 바라보는 시야를 좀 바꿔 외부 무결성과 내부 무결성에 대해 알아봄.
* 내부 무결성
- 테이블 내에 데이터나 각 테이블간의 데이터에 결함이 없음을 의미. 즉 이전에 살펴본 개체 무결성과 관계 무결성을 통칭한 의미. 이것은 보통 RDBMS의 기술적인 기능에 의해 보장. 이를 위해 RDBMS는 제약조건, 트리거, 내장 프로그램 등의 기능 제공
* 외부 무결성
- 테이블 내에 정보와 정보들이 사상하고 있는 대상에 결함이 없음을 보장. 예를 들면 회사에 근무 중인 직원이 10명인데 사원 테이블 상에 11명의 직원이 등록 되어 있고, 이들이 급여를 정상적으로 수령하는 중이라면 비록 테이블 내에 또는 테이블 간에 무결성에 문제가 없다하더라도 외부 무결성이 훼손된 것으로 간주됨. 보통 훼손된 외부 무결성 중에 최종 사용자나 관리자의 실수에 의한 경우에는 제약 조건과 여러 통제를 통해서 어느 정도 보장하는 것이 가능하지만 고의 또는 모의에 의해 훼손된 경우는 보장이 불가능. 이럴 경우는 내부 통제가 반드시 마련되어 있어야 함.
<문제>
1. 다음 테이블에 대한 표를 보고 테이블 생성을 위한 스크립트를 생성
* student

update professor
set hiredate = add_months(hiredate, 12);
20. 트랜잭션(Transaction)과 잠금(Lock)의 이해
응용 프로그램 개발 과정에서 잘못 설계된 트랜잭션으로 인해 많은 문제가 발생함 문제의 대부분은 업무 분석의 미숙이나 트랜잭션이 일으키는 잠금(Lock)에 대한 이해가 부족해서 나타나는 것들임. DBA와 같이 DBMS를 운영하는 직군의 사람들에 비해서 개발자나 사용자의 경우 이에 대한 이해가 많이 부족한 경우가 많음
트랜잭션이란
트랜잭션은 반드시 함께 실행되는 작업의 단위를 의미함. 즉 사용자의 의도에 따라 여러개의 문장으로 구성된 트랜잭션은 반드시 동시에 실행(COMMIT) 되거나 취소(ROLLBACK)됨. RDBMS는 트랜잭션을 통해 작업의 단위를 결정함으로써 작업 결과의 신뢰성을 확보
예를 들어 금융 거래 중에 계좌 이체를 생각해보면. A라는 사람이 소유 계좌의 금액 중 100만원을 B라는 사람의 계좌로 이체한다면 최소 두 가지 작업이 수행돼어야 함. 첫 번째 작업은 A의 계좌에서 100만원이 출금되는 것이고, 두 번째는 B의 계좌에 100만원이 입금되는 것임. 그런데 만약 A의 계좌에서 100만원이 출금 된 이후 두 번째 작업이 수행되기 전에 시스템이 다운된다면 B의 계좌에 돈이 입금되지 않고 A의 계좌에서만 100만원만 없어지게 될 수 있다. 이런 문제를 방지하기 위해 두 개의 작업을 하나의 트랜잭션으로 묶어 놓으면 두 개의 작업이 모두 실행되지 않으면 모두 취소됨으로 거래의 신뢰도를 높일 수 있음. 즉 두 번째 작업인 입금이 실행되지 않으면 첫 번째 출금 작업은 자동으로 취소되도록 함으로써 거래의 신뢰성을 확보하는 것. 트랜잭션은 이와 같이 더 이상 쪼갤 수 없는 최소한의 작업 단위로써 다음의 특징을 갖음
* 원자성(Aotomicity)
- 트랜잭션은 최소의 작업 단위로서 전체가 처리되거나 취소 될 수 있지만 일부만 처리 될 수는 없음
* 일관성(Consistency)
- 트랜잭션이 실행된 이후 데이터베이스의 무결성은 반드시 유지 되어야 함
* 독립성(Isolation)
- 트랜잭션을 여러 개 동시에 실행하더라도 각각의 트랜잭션은 서로 영향을 줄 수 없음.
즉 실행이 종료되지 않은 트랜잭션의 결과는 다른 트랜잭션에서 참조하는 것이 불가능
* 영속성(Durability)
- 종료된 트랜잭션의 결과는 반드시 데이터베이스에 반영되어야 함
트랜잭션의 시작과 종료
1. 시작
* 이전 트랜잭션이 종료된 이후 DML(INSERT, UPDATE, DELETE)문장이나 DDL(CREATE, ALTER, DROP, TRUNCATE), DCL(GRANT, REVOKE) 문장에 실행됐을 때 시작
2. 종료
* COMMIT이나 ROLLBACK 명령이 실행될 때 종료
* DDL이나 DCL문장의 실행이 완료되면 자동으로 종료
* 사용자의 정상 종료 시에 종료
* 데드락(Deadlock)이 걸리면 트랜잭션의 일부만 종료
트랜잭션은 하나의 세션에서 단지 하나만 시작할 수 있으며 DML인 경우 반드시 COMMIT이나 ROLLBACK으로 종료 하지만 DDL이나 DCL의 경우 문장이 실행되고 난 후 자동으로 종료. 오라클은 SAVE POINT 명령을 이용 트랜잭션의 과정을 제어 가능
트랜잭션과 언두 세그먼트(Undo segment)
DML 작업을 ROLLBACK하기 위해서는 작업 이전 데이터를 어딘가에 저장해 두어야 함. 오라클은 작업이 발생하면 즉시 테이블의 내용을 변경함으로서 DELETE나 UPDATE문을 실행하면 테이블의 정보가 즉시 변경됨. 그런데 사용자가 ROLLBACK을 실행하면 DML작업에 의해서 변경된 정보를 이전 정보로 환원해야하는데 만일 작업 이전 정보를 저장하고 있지 않다면 ROLLBACK을 실행할 수 없게 됨. 이렇게 작업 이전 정보를 저장하고 관리하는 것은 트랜잭션의 기본적인 기능이며 이를 위해 오라클은 언두 테이블스페이스와 언두 세그먼트라는 물리적인 구조를 이용. 이들은 모두 자동으로 관리되며 사용자는 이들 정보를 직접 볼 수 없고 단지 트랜잭션에서 사용.
트랜잭션 과정
테이블에 INSERT 작업이 수행될 때, 입력 데이터가 INSERT 구문이 실행될 때 테이블에 저장될지 아니면 COMMIT이 실행될 때 저장될지의 문제는 RDBMS의 구조에 따라 다름. 오라클은 INSERT문이 실행 될 때 행이 입력되고 입력된 행에만 잠금이 걸리며 COMMIT될 때 잠금이 풀림. 물론 UPDATE나 DELETE도 수행 과정은 동일. UPDATE 문장을 통해 트랜잭션 과정을 살펴보면
1. UPDATE 문장이 테이블에 발생하면, 문장 수행을 위해 사용할 언두 세그먼트(segment)를 결정
Undo Segment
ROLLBACK을 위해서는 작업 이전의 데이터를 어디엔가 보관해두어야 하고 그 장소를 undo segment라 함.
3. UPDATE 된 값이 테이블에 저장
4. 값이 변경된 행은 독점 잠금이 발생
독점 잠금이란 현재 세션 이외에는 접근을 불허하는 잠금으로 다른 세션으로 접속시에는 Undo Segment의 값을 보게 됨. 오라클에서는 행 단위로 독점 잠금을 수행하지만 SQL 서버에서는 페이지 단위로 독점 잠금을 수행. 한 페이지에 여러 행이 묶여 있기 때문에 페이지 단위로 독점 잠금을 수행하면 다른 행에도 접근하지 못할 수 있음.
5. 테이블에는 공유 잠금이 발생
6. 트랜잭션이 COMMIT 되면 잠금은 해제되고 변경된 값은 영구히 저장
7. 트랜잭션이 ROLLBACK 되면 언두 세그먼트에 저장했던 원래 값을 테이블로 환원하고 잠금이 해제
주제에서 약간 벗어난 이야기지만 트랜잭션 과정에 관해서 RDBMS의 대표적인 제품인 오라클과 SQL 서버의 차이점을 살펴보면 먼저 오라클은 그림과 같이 DML 명령어가 수행 될 때 데이터가 테이블에 적용되지만 SQL 서버는 COMMIT을 수행할 때 데이터가 테이블에 적용됨. 그리고 오라클은 행마다 독점 잠금을 걸지만 SQL 서버는 I/O 단위 인 페이지 전체에 독점 잠금을 검. 이로 인해 SQL 서버의 경우 실제 트랜잭션이 발생하지 않은 행들까지 독점 잠금이 발생할 수 있음. 간혹 이를 오해해서 오라클의 물리적인 I/O 단위를 혼동하는 경우가 있는데 오라클의 물리적인 I/O 단위는 SQL 서버의 페이지와 유사한 블록(BLOCK) 단위이긴 하지만 보통의 트랜잭션에서 잠금 대상이 아님
독점 잠금(Exclusive lock)과 공유 잠금(Share lock)
독점 잠금은 현재 세션이외에는 접근을 불허하는 잠금 방식. 이는 트랜잭션의 특징인 독립성을 보장하기 위한 것. 트랜잭션으로 행에 잠금이 발생하면 다른 세션에서는 해당 행을 검색할 수 없고, 단지 언두 세그먼트의 정보만 보게 됨. 그리고 이 때 테이블에는 공유 잠금이 발생하는데 이것은 DML 작업으로 행이 잠겨 있는 테이블에 대해서 DDL(DROP, ALTER)작업을 방지함.
실습에서 보는 바와 같이 트랜잭션은 잠금을 발생시키는데 이로 인해 잠금을 발생시킨 세션이외에 다른 세션들은 잠금이 발생한 테이블을 검색 할 때 잠금이 걸린 행에 대해서는 물리적으로 다른 영역인 언두 세그먼트를 읽음. 이에 따라 테이블의 정보가 이미 변경되었다 하더라도 이전 정보를 읽음. 이런 현상은 트랜잭션이 종료 될 때 까지 계속됨. 그러나 이렇게 지연된 트랜잭션에 의해 언두 영역을 읽는 것은 검색 시에 I/O량을 늘려서 성능을 저하시킴. 특히 OLTP(online transaction processing)와 같이 다량의 짧은 트랜잭션이 발생하는 시스템에서 지연된 트랜잭션은 시스템에 많은 부담을 줌. 이런 경우 트랜잭션을 가능하면 짧게 유지해서 이렇게 성능이 저하되는 현상을 감소 가능.
독점 잠금은 데이터에 대한 독점적인 사용을 획득하는 것으로 리소스에 걸리는 여러 개의 작업들의 독립성을 보장하는 방법임. 트랜잭션들은 실행 순서대로 행에 작업가능하고 이로 인해 대기 현상이 발생함. 오라클은 독점 잠금에 대해서 시간 순서대로 트랜잭션을 보장하며 이들 작업들은 앞의 트랜잭션이 종료되면 데이터에 대한 독점적인 접근을 보장 받음.
데드 락은 두 개의 트랜잭션이 서로 상대가 독점 락을 통해 점유한 리소스에 동시에 접근해서 둘 다 대기 상태가 될 때 발생. 데드 락은 이렇게 둘 이상의 트랜잭션이 서로 상대가 독점 락을 통해 점유한 리소스에 동시에 접근해서 둘 다 대기 상태가 될 때 발생. 데드 락은 이렇게 둘 이상의 트랜잭션이 서로 상대의 독점 락에 의해서 대기하는 현상. RDB뿐 아니라 OS등의 응용 시스템에서도 빈번히 나타나는 문제. 오라클은 데드 락을 발생시킨 세션의 마지막 명령을 보존하고 데드 락을 유발한 상대 세션의 마지막 명령을 ROLLBACK 시키는 것으로 데드 락을 해결. 이 때 세션 전체가 ROLLBACK 되는 것은 아님으로 주의.
21. 테이블 생성과 데이터 타입의 이해
DB에서 데이터를 저장하는 가장 기본적인 구조는 테이블(TABLE)임. 오라클에는 테이블 이외에 뷰(VIEW), 인덱스(INDEX), 시퀀스(SEQUENCE) 등 여러 개체가 있고 이들 중에 물리적인 공간을 갖는 개체를 세그먼트(SEGMENT)라고 분류하는데, 이 중 테이블은 사용자가 직접 조회 가능한 데이터를 저장하는 유일한 세그먼트임. 테이블은 DB에서 가장 중요한 개체이며 최종 사용자에게 DB는 단지 테이블의 모임으로 보일 만큼 테이블은 가장 핵심적인 단위임.
> 테이블 생성과 삭제
테이블은 행(Row)과 컬럼(Colum)으로 이루어진 매우 익숙한 형태의 자료구조임. 테이블과 같은 구조의 자료구조는 문서의 일반적인 형태로 DB 이전부터 사용되어 옴. 정보시스템과 무관하게 문서로 널리 사용되는 이것을 행과 열로 구성된 표 또는 도표라 부름.
정보 시스템에서 문서의 형태였던 도표의 구조를 도입해서 테이블로 사용한 것임. 초창기 파일 시스템을 기반으로 한 DB 시스템에서 레코드와 필드로 구성된 파일이 도표를 대신했찌만 RDB(Relatinal DataBase)가 본격적으로 사용되면서부터 행(Row)과 컬럼(Column)으로 구성된 테이블이 이를 대신.
SQL>CREATE TABLE 테이블 (
2 컬럼 데이터_타입 [DEFAULT default 값] [컬럼 레벨 제약조건],
3 컬럼 데이터_타입 [DEFAULT default 값] [컬럼 레벨 제약조건], 4 .............
5 [테이블 레벨 제약조건],
6 ........
7 );
* 데이터_타입
- 컬럼에 입력될 데이터의 종류와 크기를 결정
* DEFAULT
- 입력이 누락됐을 때 기본 입력 값을 정의
- Default 값을 지정하지 않으면 널 값이 저장
* 컬럼 레벨 제약 조건
- PK, FK, UK, CHECK, NOT NULL 등을 지정
* 테이블 레벨 제약 조건
- PK, FK, UK, CHECK 만 지정
- NOT NULL은 정의 불가
SQL>DROP TABLE 테이블
2 [CASCADE CONSTRAINT];
* 테이블을 삭제함
- OS와 비슷하게 테이블을 물리적으로 삭제하지 않고 휴지통에 넣어두어 나중에 복구 가능하도록 함.
- 공간이 부족하면 휴지통의 공간은 자동으로 재사용
- 삭제된 테이블은 BIN$로 시작하는 이름이 할당
* CASCADE CONSTRAINT : 테이블이 다른 테이블로부터 참조되는 경우 해당 제약 조건을 먼저 삭제한 후 테이블을 삭제
SQL>PURGE RECYCLEBIN;
* 휴지통에 저장된 모든 내용을 깨끗이 삭제
SQL>SELECT table_name
2 FROM user_tables;
* 'SELECT * FROM tab' 과 동일하게 소유한 테이블 목록을 검색
* user_tables와 같이 오라클의 메타 정보를 저장하고 검색하는 테이블을 데이터 딕셔너리 (Data Dictionary) 또는 딕셔너리(Dictionary)라 함
* user_tables에는 소유한 테이블 이름뿐 아니라 테이블의 물리적인 상태를 포함한 테이블에 대한 다양한 정보가 저장
SQL>SELECT table_name, column_name, data_type, data_length
2 FROM user_tab_columns
3 [WHERE table_name = 테이블;]
* 'DESC 테이블'과 동일한 내용을 검색
* User_tab_columns를 이용해서 테이블의 구조를 검색
* data_type : 컬럼의 데이터 타입
* data_length : 컬럼의 길이
테이블 생성에서 이름 규칙
* 문자로 시작
* 30자 이내
* 영문, 숫자, _, $, #만을 사용
- 한글 사용은 가능하지만 되도록 사용하지 않는 것이 좋음.
* 테이블의 이름은 동일한 유저(스키마) 안에서 유일해야 함
* 예약어는 사용이 불가능
* 대소문자를 구별하지 않음
- 생성 할 때 사용한 문자와는 관계없이 모든 이름은 대문자로 정의
- 테이블 이름은 딕셔너리에 저장되는데, 모두 대문자로 저장
데이터 타입
* 오라클은 다양한 데이터 타입을 제공
* 문자 타입
- VARCHAR2, CHAR, LONG, CLOB
* 숫자 타입
- NUMBER
* 날짜 타입
- DATA
* 이진 타입
- RAW, LONG RAW, BLOB, BFILE
* ROWID 타입
- ROWID
오라클에는 우리가 사용하는 어떤 언어보다도 많은 데이터 타입을 제공. 그러나 이것들은 대부분 PL/SQL 이라는 프로그래밍을 위해 제공되는 것들임. 일반적인 SQL문에서 이들을 사용하는 것은 별가치가 없음.
VARCHAR2, NUMBER, DATE 타입으로, 이 세 가지 타입이 전체 테이블의 99% 이상 사용.
실무에서 어떤 컬럼의 데이터 타입을 정할 때 숫자인지 문자인지 결정하는 것은 결코 간단하지 않음. 예를 들면 계좌번호, 주민번호, 사번, 학번, ... 등과 같이 경계가 모호한 데이터들이 주변에 많기 때문임. 주민번호의 예를 들어 보면, 주민 번호는 숫자라고 생각 할 수 있지만, 문자임. 어떤 사람의 주민번호 앞자리가 061311이고 만약 이것이 숫자였다면 이것을 읽을 때 '육만삼천삼백십일'이라고 읽었을 것임. 하지만 이 값을 읽을 때 대부분의 사람들은 '영육일삼일일'이라고 읽음.
무엇이 문자이고, 숫자인지에 대한 명확한 답은 없지만 일반적이고 상당한 이유가 있는 답은 존재함. 그것은 컬럼의 데이터가 연산의 대상이 되는 것은 숫자로 정의하고 그렇지 않은 것은 일단 문자로 구별하는 것. 연산의 대상이 될 수 있는 예를 보면 월급, 보너스, 좌석의 수, 사원의 수 .. 등이 있음. 이들은 당연히 숫자형임. 반대로 연산의 대상이 아닌 경우는 사번, 학번 등이 있음. 앞에 예로든 주민 번호의 예를 보면, 주민번호를 대상으로 +,-,/,* 등의 사칙연산을 수행한 결과 값이 의미를 갖는다면 이것은 숫자, 하지만 의미가 없다면 문자로 간주함
데이터 딕셔너리(Data Dictionary)
데이터 딕셔너리는 데이터베이스의 상태나 내부 운영과 관련된 정보를 저장해주는 테이블.
이들 테이블을 물리적으로 특별한 공간에 저장되며 각 사용자의 관리 레벨에 따라 접근 가능한 목록이 달라짐. 보통은 DBA가 RDBMS를 관리하기 위해 사용하지만 일반 사용자도 자신의 여러 개체에 대한 정보를 조회하기 위해 사용 가능. 실제 딕셔너리 테이블들은 직접 검색하는 것이 아니라 뷰를 통해 검색하지만 어떤 경우든 SELECT 만 가능함으로 이를 구별 하는 것은 별 의미 없음.
딕셔너리는 원도우즈의 제어판과 비슷한 기능을 가진 것으로 이름이 항상 복수형이라는 특징 보유
딕셔너리 이름의 접두어
딕셔너리는 이름의 접두어만으로 접근 레벨을 짐작 할 수 있음. 접두어는 'DBA_', 'ALL_', 'USER_' 이렇게 세 가지가 있으며 각각의 의미는 다음과 같음
* DBA_ : 관리자만 검색 가능한 딕셔너리에 붙는 접두어
(DBA_TABLES, DBA_INDEXES, DBA_TABLESPACES, DBA_DATA_FILES, ...)
* ALL_ : 일반 사용자가 검색 가능한 딕셔너리, 접근 가능한 개체에 대한 정보를 담고 있음
(ALL_TABLES, ALL_CONSTRAINTS, ALL_INDEXES, ALL_VIEWS, ...)
* USER_ : 일반 사용자가 검색 가능한 딕셔너리, 소유하고 있는 개체에 대한 정보를 담고 있음
(USER_TABLES, USER_CONSTRAINTS, USER_INDEXES, USER_VIEWS, ...)
관리자는 DBA_ 접두어를 가진 딕셔너리를 이용하고 일반 사용자는 보통 USER_ 접두어를 가진 딕셔너리를 이용하는 데 11g 버전 기준으로 DBA_ 딕셔너리는 대략 700여개, USER_ 딕셔너리는 대략 400여개가 있음. 딕셔너리 목록은 DICT 테이블을 통해서 검색 가능함.
DICT 테이블의 전체 검색 결과는 현재 사용자가 접근 가능한 딕셔너리의 목록이므로 사용자와 무관하게 사용 가능.
22. 제약조건 이해와 설정 1 : PK, FK
제약 조선이란 테이블 단위에서 데이터의 무결성을 보장해주는 규칙. 제약 조건은 테이블에 데이터가 입력, 수정, 삭제되거나 테이블이 삭제, 변경될 경우 잘못된 트랜잭션이 수행되지 않도록 결함을 유발할 가능성이 있는 작업을 방지하는 역할을 담당. 특히 PK(Primary Key)와 FK(Foreign Key)는 테이블의 필수 요소로써 모든 테이블은 이들 둘 중 하나 이상을 반드시 포함하고 있음.
제약 조건
* 테이블 단위에서 정의되고 적용됨
* 종속성이 존재하는 경우 테이블의 삭제를 막음
* 자료가 삽입, 갱신, 삭제될 때마다 규칙이 적용.
* 일시적으로 활성화하거나 비활성화 하는 것이 가능
* USER_CONSTRAINTS, USER_CONS_COLUMNS 딕셔너리에서 검색
* 제약 조건은 개체처럼 관리되므로 반드시 이름이 필요. 제약 조건에 이름을 정의하지 않으면 오라클 서버가 자동으로 SYS_Cn 형태의 이름을 붙임
오라클에서 제공되는 제약조건들
* PRIMARY KEY
* FOREIGN KEY
* UNIQUE KEY
* NOT NULL
* CHECK
> PK와 FK의 정의
PK(Primary Key, 주키, 주식별자)
- PK는 테이블의 모든 데이터를 유일하게 식별해주는 컬럼. 예를 들어 데이터베이스에는 여러분을 나타내는 정보가 여러가지가 있음. 이름, 성별, 주소, 출신 학교 등등.. 이 중에 어떤 데이터가 연속적으로 여러분을 유일하게 구분 할 수 있는 데이터 인지 생각해보면 됨.
- 이 중에 주민번호, 학번, 사번 등의 데이터는 중복 없이 여러분의 데이터를 유일하게 구분 할 수 있도록 해주는 데이터 들임. 이들 데이터가 바로 PK가 됨. 이런 이유로 PK는 중복되지 않으면서 NULL일 수 없는 컬럼이 선택. 만일 PK를 주민번호로 했다면 이 때 이름이나 성별등의 데이터는 PK인 주민번호에 의해서 식별 됨. 다르게 표현하면 PK인 주민번호에 대해서 이름, 성별, 주소 등은 함수적 종속(functional dependency) 관계에 있다고 표현. PK의 가장 중요한 정의는 함수적 종속이라는 수학적인 정의임. PK가 없다면 RDB에서 그건 테이블이 될 수 없음.
FK(Foreing Key, 외부키, 외부식별자)
- FK는 테이블 간 관계(Relationship)를 의미. 사원 테이블의 부서번호 컬럼은 각 사원이 소속된 부서의 번호가 저장된 컬럼. 이 때 사원은 당연히 회사에 존재하는 부서에만 소속될 수 있음. 만일 회사에 총무부와 회계부서만 존한다면 모든 사원은 반드시 이 두 부서에만 속해야 함. 만일 어떤 사원이 존재하지 않는 부서에 소속된다면 어떨까? 이것은 부서 테이블을 확인함으로써 확인 가능함. 즉 사원 테이블의 부서번호 컬럼에는 부서 테이블의 부서번호 컬럼에 존재하는 데이터만 입력 가능함. 그런데 입력하는 사람이 입력 시점에 일일이 이를 확인하는 것은 어려운 일임. 이런 경우 사원 테이블의 부서 번호 컬럼에 FK를 설정해서 부서 테이블의 부서번호 컬럼을 참조하도록 한다면 사용자가 부서 테이블에 존재하지 않는 부서번호를 사원 테이블에 입력하는 것을 DBMS가 자동으로 막아줌. 이 때 우리는 사원 테이블과 부서 테이블 간에 관계라 하고 관계는 주로 FK로 표현.
> PK(Primary Key), FK(Foreign Key) 설정과 조회
- Primary Key 설정
SQL> CREATE TABLE 테이블 (
2 **내용**
3 CONSTRAINT 제약_조건 PRIMARY KEY (컬럼)
4 );
SQL> CREATE TABLE 테이블 (
2 컬럼 데이터_타입 CONSTRAINT 제약_조건 PRIMARY KEY, ****
* 테이블을 생성할 때 PK를 정의
* PK는 각 행을 고유하게 식별하는 역할을 담당
* 테이블 당 하나만 정의 가능
* 지정된 컬럼에는 중복된 값이나 NULL값이 입력 될 수 없음
* PK로 지정 가능한 컬럼이 여러 개 있을 때는 검색에 많이 사용되고 간단하고 짧은 컬럼을 지정
* 주 식별자, 주키, 주식별자 등으로 불림
* 고유 인덱스(Unique Index)가 자동으로 생성
- Foreign Key 설정
SQL> CREATE TABLE 테이블 (
2 ****
3 CONSTRAINT 제약_조건 FOREIGN KEY (컬럼)
4 REFERENCE 참조할_테이블 (참조할_컬럼) [ON DELETE CASCADE]);
SQL> CREATE TABLE 테이블 (
2 컬럼명 데이터_타입 CONSTRAINT 제약_조건 FOREIGN KEY
3 REFERENCES 참조할_테이블 (참조할_컬럼)
4 [ON DELETE CASCADE],
5 *************
* 테이블을 생성할 때 FK를 정의
* FK가 정의된 테이블이 하위(자식) 테이블
* 참조되는 테이블이 상위(부모) 테이블
* 상위 테이블은 미리 생성되어 있어야함
* 상위 테이블의 참조되는 컬럼에 존재하는 값만을 입력 할 수 있음
* 상위 테이블에 참조되는 행의 데이터는 FK를 위배하는 삭제나 변경이 불가능
* 상위 테이블은 FK로 인해 삭제가 불가능
* ON DELETE CASCADE : 참조되는 상위 테이블의 행에 대한 DELETE를 허용
- 하위 테이블의 행도 같이 지워짐
* 자료형이 반드시 일치해야 함
* 참조되는 컬럼은 PK이거나 UK(Unique Key)만 가능
* 외부키, 참조키, 외부 식별자 등으로 불림
▲
- 제약조건을 정의하는 방법은 NOT NULL을 제외하고 두 가지 방법이 제공.
하나는 컬럼을 정의하면서 같이 정의하는 방법으로 컬럼 레벨 정의라고 하고 하나는 테이블 생성 명령어 마지막에 기술하는 방법으로 테이블 레벨 정의라 함. 둘 중 어떤 것을 사용해도 상관없지만 가능한 테이블 레벨 정의를 사용하는 것이 가독성이 높음
제약 조건 조회
SQL> SELECT c.table_name, c.constraint_name, c.constraint_type, s.colum_name
2 FROM user_constraints c, user_cons_columns s
3 WHERE c.constraint_name = s.constraint_name
4 AND c.table_name in (검색_대상_테이블_목록)
5 ORDER BY c.table_name;
* 테이블에 정의된 제약 조건을 검색
* 'AND c.table_name in (검색_대상_테이블_목록)' 부분을 생략하면 소유한 모든 테이블의 제약조건을 검색
* constraint_name : CONSTRAINT 이름
* constraint_type : CONSTRAINT 타입
- P(PK), R(FK), U(UK), C(NOT NULL, CHECK)
SQL> SELECT p.table_name 상위테이블, p.constraint_name 상위제약조건,
2 c.table_name 하위테이블, c.constraint_name 참조제약조건
3 FROM user_constraints p, user_constraints c
4 WHERE c.r_constraint_name=p.constraint_name
5 AND p.table_name in (검색_대상_테이블_목록)
6 ORDER BY p.table_name;
* 지정한 테이블을 참조하는 테이블의 목록을 확인
* 하위 테이블이 존재하는 상위 테이블은 테이블 삭제가 불가능
테이블 상세 도표
- 테이블 상세 도표는 테이블의 구조를 한 눈에 파악 할 수 있는 간단한 도표임. 테이블의 구조와 관계는 보통 ERD(Entity-Relationship Diagram)를 이용하지만 본서가 모델링 과정을 다루지 않는 관계로 각 테이블의 정보를 도표로 정리 한 것. 보통 개체 상세도라고도 불리는 상세도에서 우리에게 필요한 부분만을 발췌함. 이를 통해 테이블의 구조, 참조 관계등을 명확히 파악할 수 있음. 테이블을 생성하기 전에 반드시 테이블에 대한 작업 계획이 완성돼야 하는데 그 중 가장 중요한 것이 이들 상세도표임.
▲ 내부 무결성과 외부 무결성
- 무결성은 데이터에 결함이 없음을 보장하는 성격을 의미. 이미 앞에서 개체 무결성과 관계 무결성에 대해서 살펴봄. 이번에는 무결성을 바라보는 시야를 좀 바꿔 외부 무결성과 내부 무결성에 대해 알아봄.
* 내부 무결성
- 테이블 내에 데이터나 각 테이블간의 데이터에 결함이 없음을 의미. 즉 이전에 살펴본 개체 무결성과 관계 무결성을 통칭한 의미. 이것은 보통 RDBMS의 기술적인 기능에 의해 보장. 이를 위해 RDBMS는 제약조건, 트리거, 내장 프로그램 등의 기능 제공
* 외부 무결성
- 테이블 내에 정보와 정보들이 사상하고 있는 대상에 결함이 없음을 보장. 예를 들면 회사에 근무 중인 직원이 10명인데 사원 테이블 상에 11명의 직원이 등록 되어 있고, 이들이 급여를 정상적으로 수령하는 중이라면 비록 테이블 내에 또는 테이블 간에 무결성에 문제가 없다하더라도 외부 무결성이 훼손된 것으로 간주됨. 보통 훼손된 외부 무결성 중에 최종 사용자나 관리자의 실수에 의한 경우에는 제약 조건과 여러 통제를 통해서 어느 정도 보장하는 것이 가능하지만 고의 또는 모의에 의해 훼손된 경우는 보장이 불가능. 이럴 경우는 내부 통제가 반드시 마련되어 있어야 함.
<문제>
1. 다음 테이블에 대한 표를 보고 테이블 생성을 위한 스크립트를 생성
* student